Multiple Agents Interaction
Collaborate and/or compete to solve a task
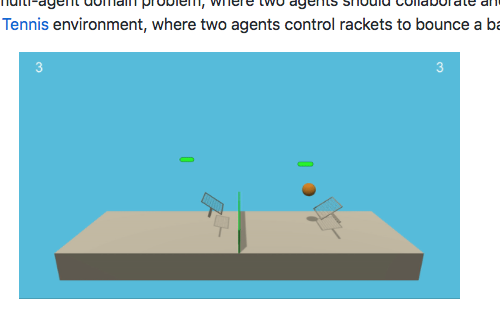
In this project, I solved a multi-agent domain problem, where two agents should collaborate and/or compete to deal with a task. I worked with the Tennis environment, where two agents control rackets to bounce a ball over a net. I implemented the Multi-Agent Deep Deterministic Policy Gradient (DDPG) model, uwing a actor-critic architecture to deal with the high-dimensional action space.
This project is connected to the Deep Reinforcement Learning Nanodegree, from Udacity. I used Python, Unity ML toolkit and Pytorch.